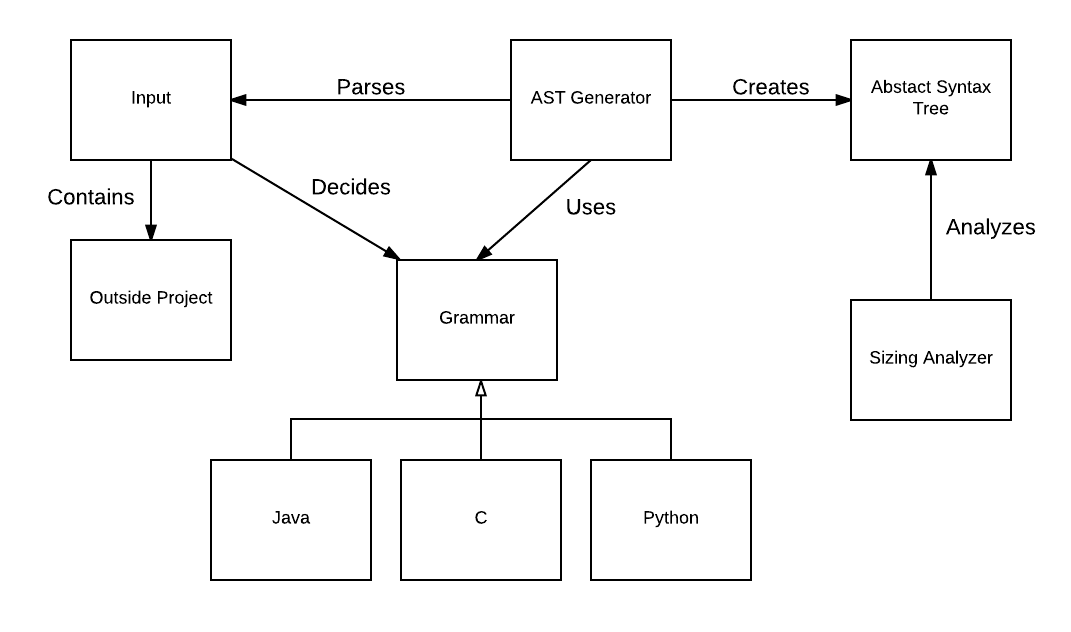
For this project, we will be taking a scrum approach with some modifications to better fit the research theme.
This project is an exploratory and research based project. As it stands, the project does not have a long list of concrete requirements or expected features. We won't know what can be achieved with this project until we start development and testing. There will be a lot of communication with the project sponsor to determine the direction that the project should go. Therefore, we want to take an iterative approach to development, specifically using an agile methodology, scrum. Overall, the sprints will be exploratory in nature at the start of development. We need initial sprints of development to determine how the rest of the project will go. A sprint of development will be completed, the results will be discussed with the project sponsor, and new tasks will be decided on based on our progress and requirements at that time.
Instead of strict user stories, we will be developing in iterations according to questions that we pose, and then tracking the number of questions we have answered in an iteration with the time spent as well. An example of a question might be "are open source grammars for Java sufficient for parsing Java source code?" We will not be able to estimate the size of question tickets, especially at the start of this project. Overall, we will limit the time spent on one question ticket to a single sprint unless there is a need to explore it further, at which point we will discuss the question with the project sponsor and decide if more effort should be spent. We will use sprints of two weeks. One week sprints would not be feasible as we are not working forty hours every week on this project. In addition, most of the research tickets may take a longer amount of time than typical, feature driven user stories. Physical daily standup meetings will not be possible because of this being an in-class project.