The following domain model is a representation of the real-world entities that describe the RocReadaR application and how they operate.
It can be accessed with proper permissions here: https://drive.google.com/file/d/0B-FkFm0Jd0pYNWpsdTU5S1hxWjg/view?usp=sharing
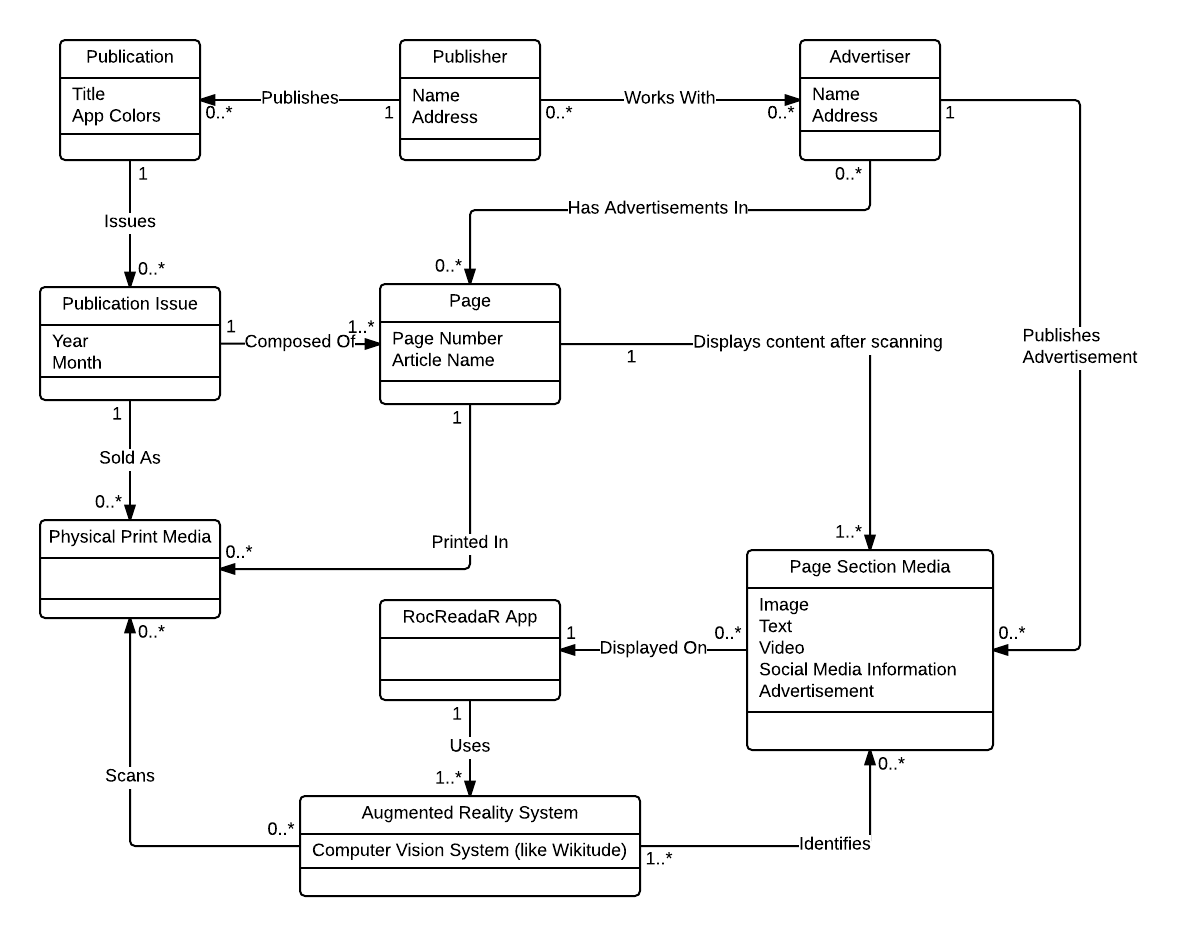
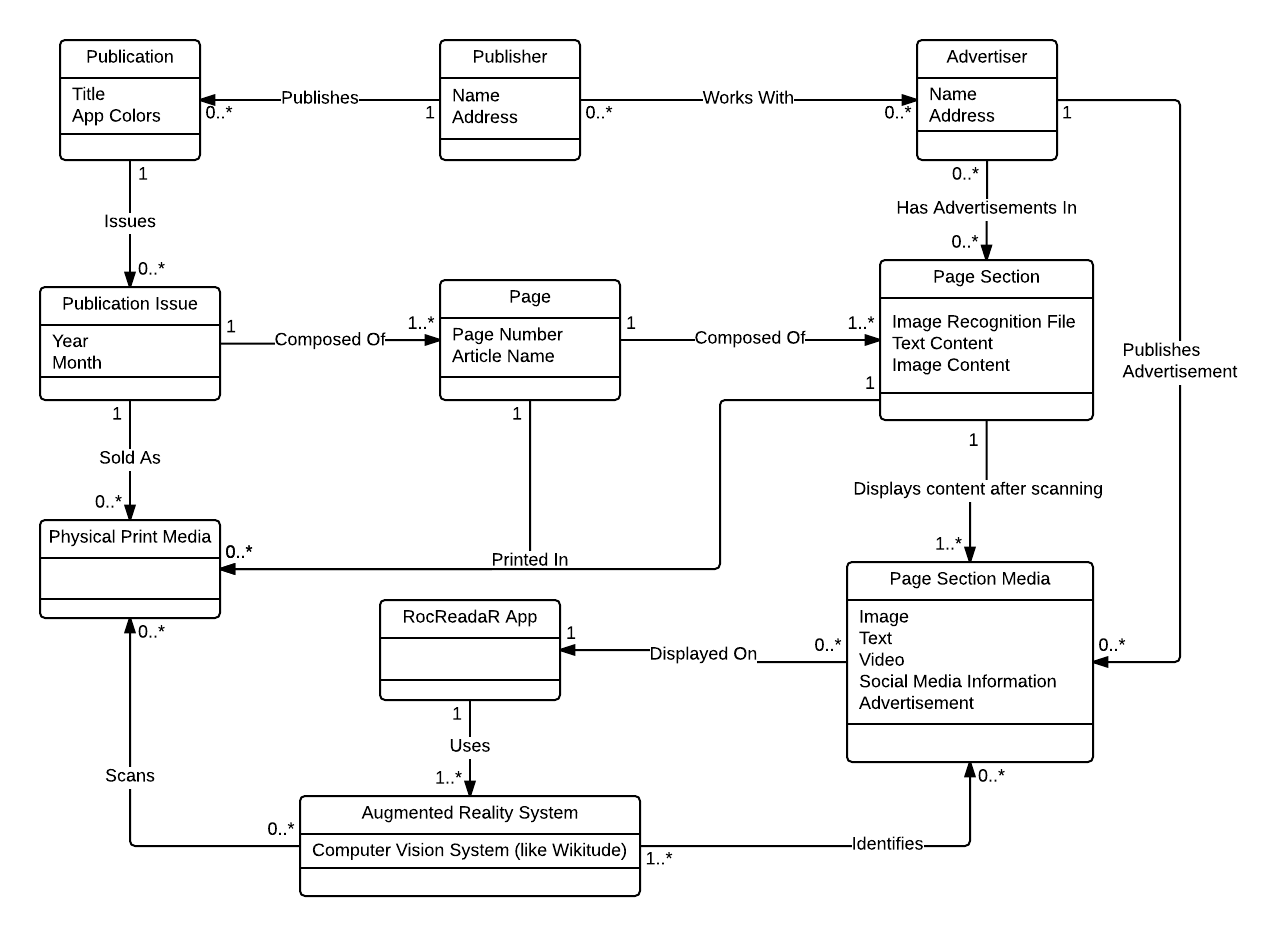
Element Catalog
- Publication
- A publication is a printed type of media that is repeatedly printed (as publication issues). The main example is a magazine, but this could encompass other types like newsletters, newspapers, catalogs, etc.
- A publication is managed by one publisher.
- Publisher
- The publisher is the company or group of people who manage the content of the publication.
- A publisher may manage many publications.
- Advertiser
- An advertiser is the company that produces advertisements that are online or printed in media.
- Advertisers and Publishers may work together in order to create advertisements that can create revenue. Advertisers may wish to place advertisements in publications.
- Publication Issue
- A publication issue is one printed issue of a publication. For example, it could be the May 2015 issue of a magazine. These are not limited to Year and Month, but in most cases will be classified in this manner.
- Page
- A page is a single page with all its content in a publication issue. Pages are recognized by the image recognition system.
- Page Section Media
- Page media is media (like videos, images, facebook links, other web links) that are associated with a page. Using an augmented reality system, this media will be displayed when a page is scanned.
- Physical Print Media
- Physical print media is an real-life instance of an actually printed publication issue.
- RocReadaR App
- The RocReadaR App is the mobile application developed by the RocReadaR team to scan publication pages and display media.
- Augmented Reality System
- The Augmented Reality System is a computer system or component that recognizes images. This may or may not be part of the RocReadaR App, but is an important part of the system. This component will recognize images of the pages, so that the proper media can be displayed.
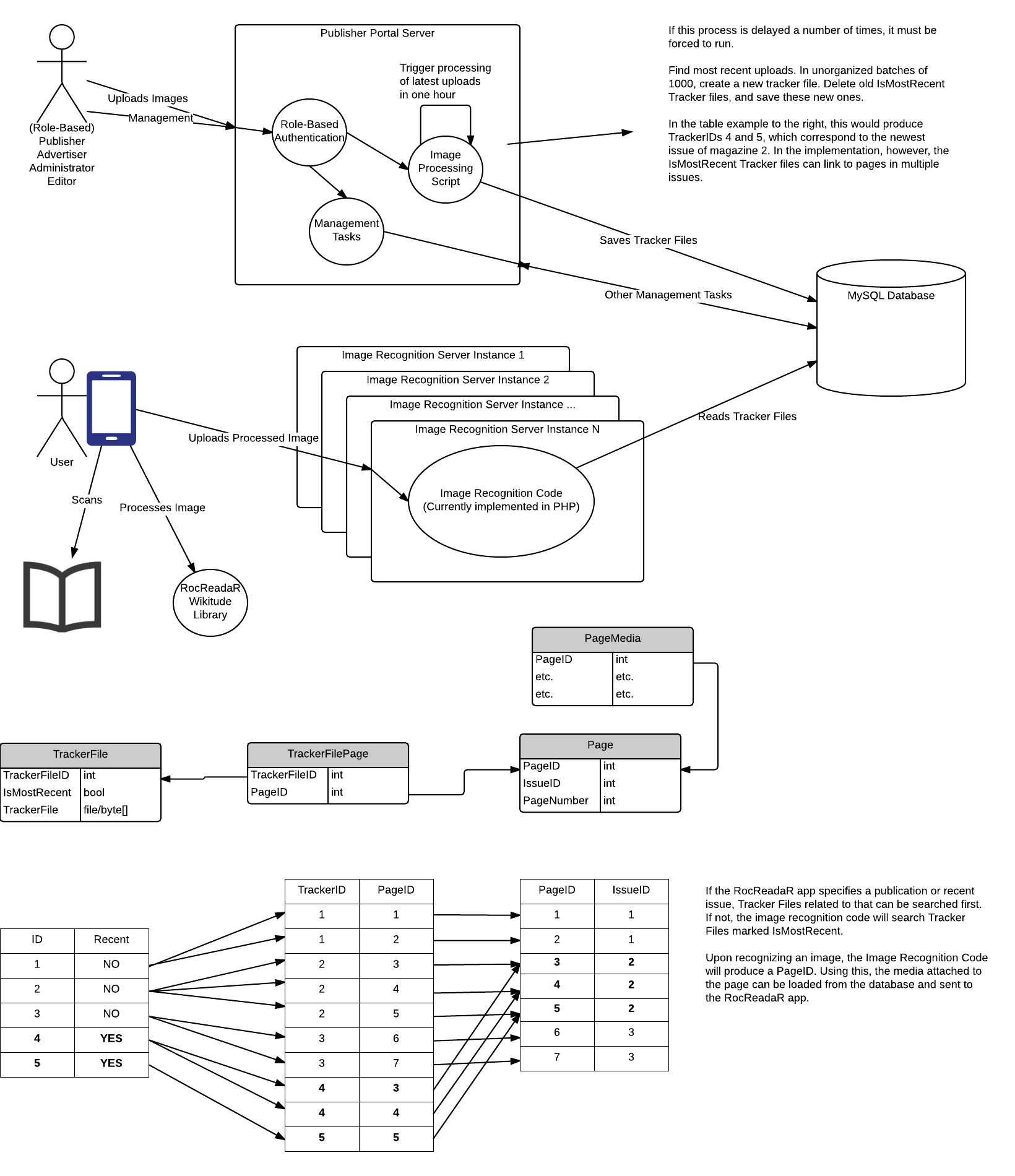
The following diagram combines many aspects of the architecture, giving insight into the modules, deployment, and runtime plans for the architecture.
It can be accessed with proper permissions here: https://drive.google.com/a/g.rit.edu/file/d/0B8ALJia9jVzAOGVka2RaQjhtQmM/view?usp=sharing
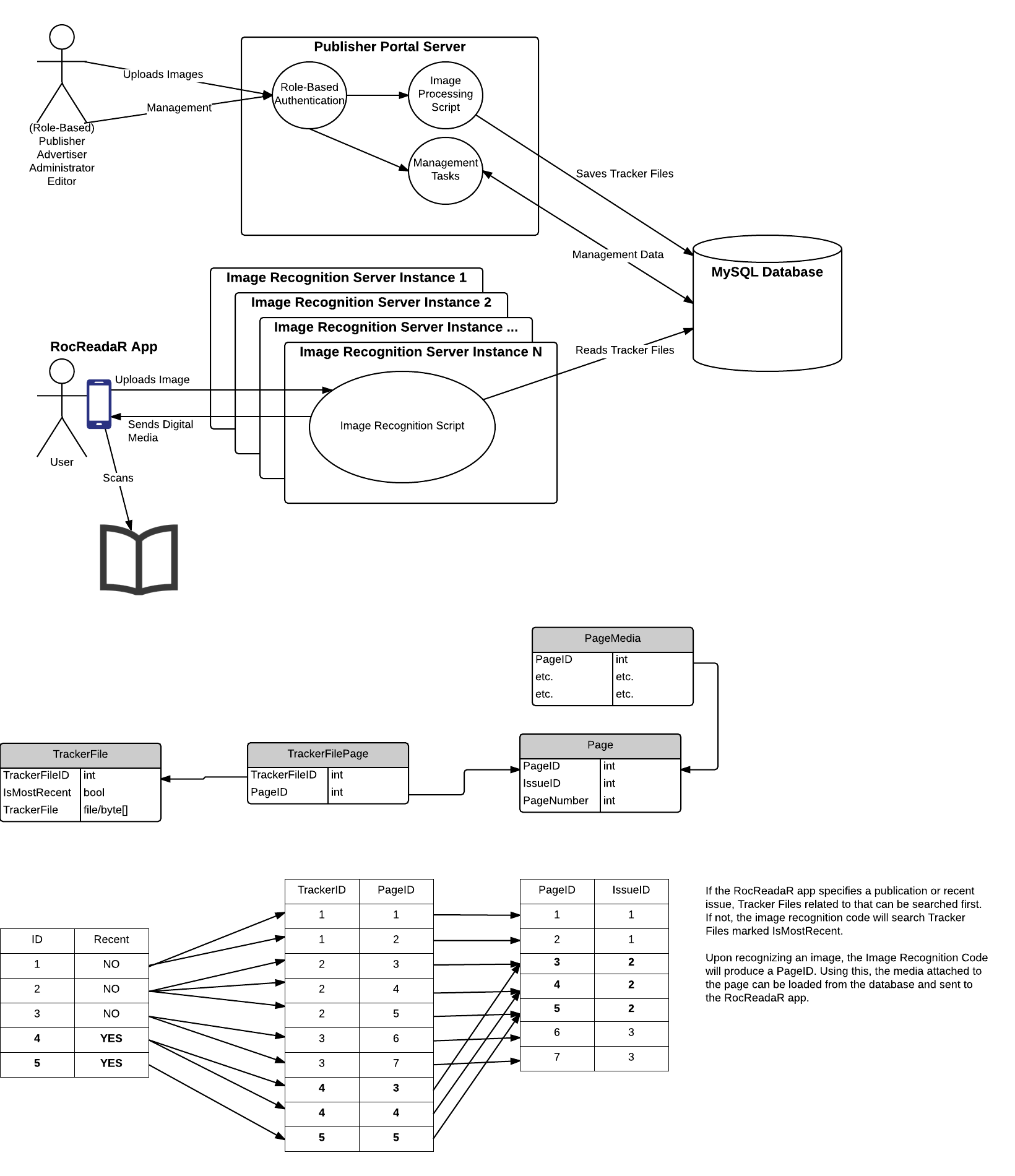
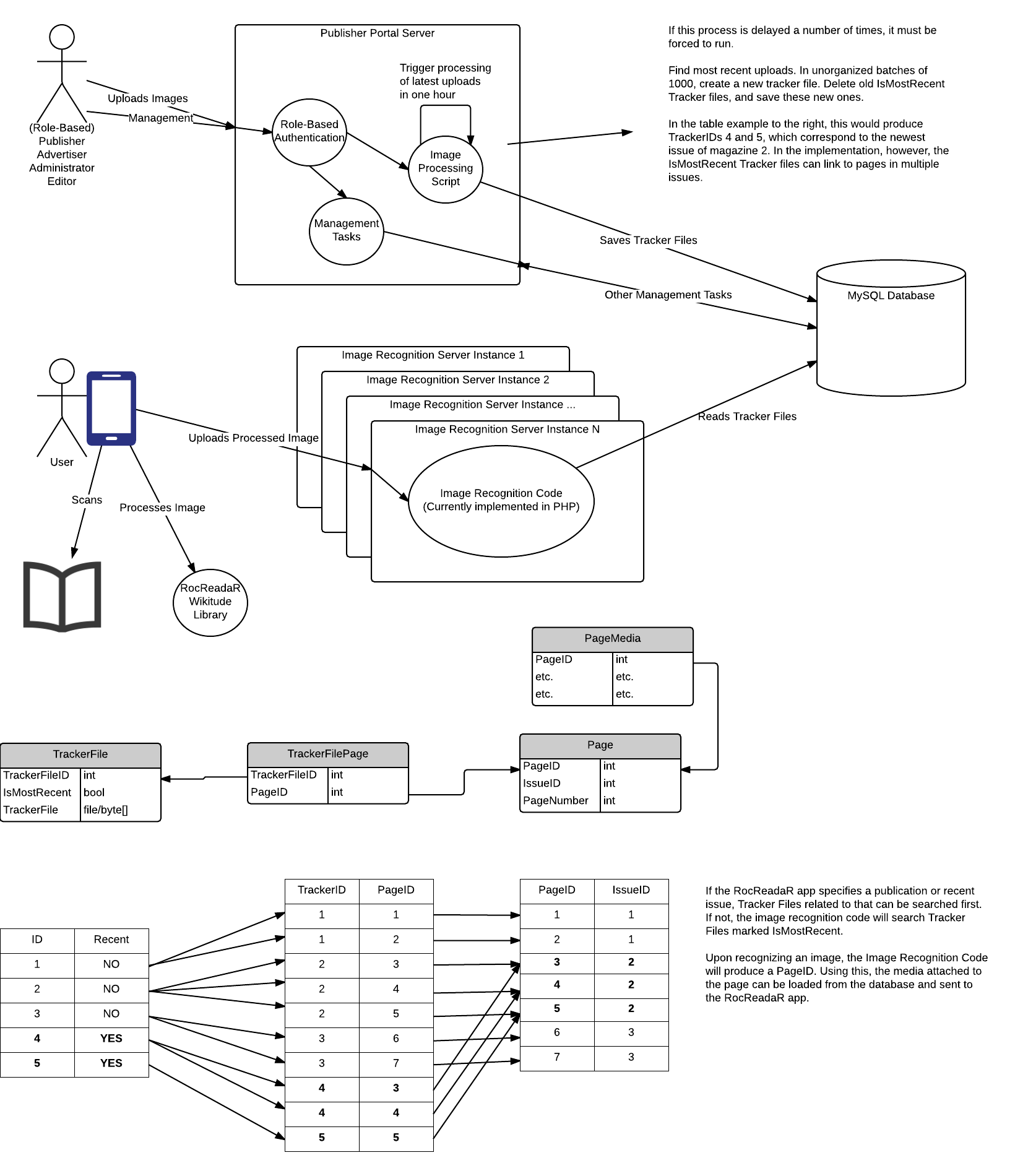
This diagram shows a high-level overview of many aspects of the system.
RocReadar App
The RocReadaR App is the mobile application developed by the RocReadaR team to scan publication pages (of things like magazines) and display media. Users can use the application to "scan" a physically printed piece of media. When the printed media is recognized, media is shown. For example, a printed piece of media may have an article on a presentation that happened at RIT. When scanned using the RocReadaR App, a video of the presentation is shown. Many types of media can be shown.
Image Recognition Servers
Due to scaling issues, image recognition cannot be done on the RocReadaR App itself. Users phones would not be able to download all possible pages that could be recognized. Therefore, recognition needs to occur on our own servers. These are the Image Recognition Servers.
Publisher Portal
The Publisher Portal provides the functionality for the different manager users of the system to create, edit, and otherwise manage how image recognition occurs and what media is presented after image recognition occurs. Users (Publishers, Advertisers, etc. - NOT RocReadaR users) can log in and provide images to be recognized. They can then provide and edit the media that is shown upon image recognition.
Different roles are defined for the publisher portal. The roles are:
- Administrators
- Technical users who manage the system (like developers)
- Editors
- Users who manage the whole system (the owners/sponsors)
- Publishers
- Users who create and manage publication media
- Advertisers
- Users who are granted permission to create and manage publication media for a limited set of pages.
When image recognition files have been uploaded, they need to be processed into ".wtc" files. these files should be organized in a way that makes image recognition optimal. Therefore, after uploading images, the system should save the file, then wait 1 hour, then run the optimization process.
MySQL Database
All data, including recognition and media files, should be stored and read from the database. Images or other media can be located on a separate server, and recognition can send simply a URL (this is just a different type of media).
Tracker File Optimization
In the middle of the overview, there is a segment of a schema diagram. Page media is linked to a page. Tracker files may contain many images, therefore there is a table of tracker files, and a table linking tracker files to the pages they recognize (TrackerFilePage). This way, a tracker file can be linked to any number of pages.
Tracker File Organization is documented here: WTC File Processing Optimization
A Tracker File Searching Algorithm is documented here: V2 Endpoint Search Ordering
{kind=link}
{kind=link}
{kind=link}
{kind=link}